
PS1 - 05: HOW MANY MAKES A CROWD? AN ADAPTIVE STRATEGY FOR CROWD RECRUITMENT FOR SURGICAL SKILL ASSESSMENT.
Anand Malpani, PhD, Narges Ahmidi, PhD, Lisa Ishii, MD, MHS, S. Swaroop Vedula, MBBS, PhD, Gregory D Hager, PhD, Masaru Ishii, MD, PhD; Johns Hopkins University
Objective: To determine whether an adaptive strategy to recruit crowds for surgical skill assessment yields reliable and valid ratings at a lower cost than recruiting crowds of a fixed size.
Methods: We recruited 5 faculty experts (FE) and at least 23 crowd workers (CW) on Amazon Mechanical Turk (AMT) to rate technical skill for endoscopic sinus surgery tasks. To compare reliability and validity with different sizes of CW, we used a dataset of FE and CW ratings for overall skill (binary; good/bad) on 36 task instances. We repeatedly subsampled k = 3, 5, 7, and 9 CW ratings for each task (999 iterations). We compared inter-rater agreement between FE and CW using Fleiss’ kappa. We computed accuracy of CW using FE ratings as groundtruth. We used a separate dataset of 293 task instances to estimate cost savings using adaptive recruitment of CW. In this strategy, if percent agreement between the first 3 CW is below 75% then we recruit an additional 2 CW, and repeat upto a maximum of 9 CW. We calculated cost in terms of CW units (1 unit = 1 CW rating a task).
Results: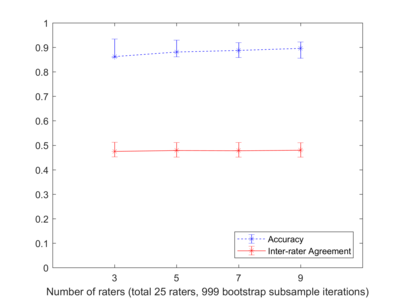
Figure 1 illustrates that fewer CW ratings did not result in a significant drop in reliability (solid line; 0.47, 0.48, 0.48, and 0.48) or validity (dashed line; 0.86, 0.88, 0.89, and 0.90) for 3, 5, 7, and 9 CW respectively. Using the adaptive recruitment strategy, 172 task instances required 3 CW, 70 required 5 CW, 3 required 7 CW, and 48 required 9 CW. This corresponds to a total of 1319 CW units compared with 2637 CW units if a fixed sample of 9 CW were recruited for all task instances.
Conclusions: Adaptive recruitment of CW from AMT for surgical skill assessment yields substantial cost savings (50% reduction) without significant loss in reliability and accuracy (4% reduction). Adaptive recruitment of CW accounts for task complexity to enable efficient, scalable crowdsourcing for surgical skill assessment.